
Rewriting Tempo schema in Parquet for blazin' fast search.
This is a blog version of the talk I gave at GrafanaCON 2022.
Transcript

Today I’d like to talk to you about how we’re using Apache Parquet to bring blazing fast search to Tempo.
Before I get started, I’d like to quickly recap the history of implementing search in Tempo. We launched Tempo in October 2020. Back then it was a key-value store with a strong integration with Loki and Prometheus to enable trace discovery. In June 2021 we launched Tempo 1.0, marking the key-value storage table and the cloud-hosted traces as generally available. This was a milestone because beyond this the team really started focusing on implementing the next key feature around searching over trace data.

In November 2021 we launched search over recent data that we store in ingesters. To do this we use the complementary flat buffer–based search. We built an index along with the proto data on the side. Soon after, in January 2022, we launched full backend search using serverless technologies. This would launch cloud functions to search over product data present on the object store backend. But as we implemented fallback search we realized that we needed to fundamentally change the backend and format to enable queries over large data sets, unlock queries over more than 24 hours, and also unlock three SQL. This is why we started really investing into Parquet as the new storage format of choice.
Apache Parquet
So what is Parquet? Parquet is an open standard under the Apache Foundation, and to quote from their website, Apache Parquet is an open source column-oriented format.
Parquet is a data file format designed for efficient data storage and retrieval. For Tempo that means we can store and access trace data more efficiently—a topic I’ll unpack in the following sections—and, as an operator, it unlocks a whole ecosystem of tooling that already works against Parquet files and object storage.
Those tools include Presto, Spark, Flink, and many others. The advantage is that these engines also unlock popular query languages like SQL, which opens the door for many more folks across the industry to write SQL queries on top of trace data without touching the bespoke query layer.
Now let’s look at what storing traces in Parquet actually looks like in practice. A trace typically has an ID, a start and end time, and a series of spans. Each span has a name, service, tags, and often an associated event or log line.

I’m going to lay those schema attributes out a bit differently to make it intuitive to work with Parquet files, and in the slides I colorize them to keep things visual. The end result is a block of traces where every row represents a trace and every column represents an attribute shared across the traces. For this walkthrough we’ll assume that schema stays consistent so we can reason clearly about how the storage format behaves.
From there we zoom into four key features that Apache Parquet unlocks for efficient search.
Encodings
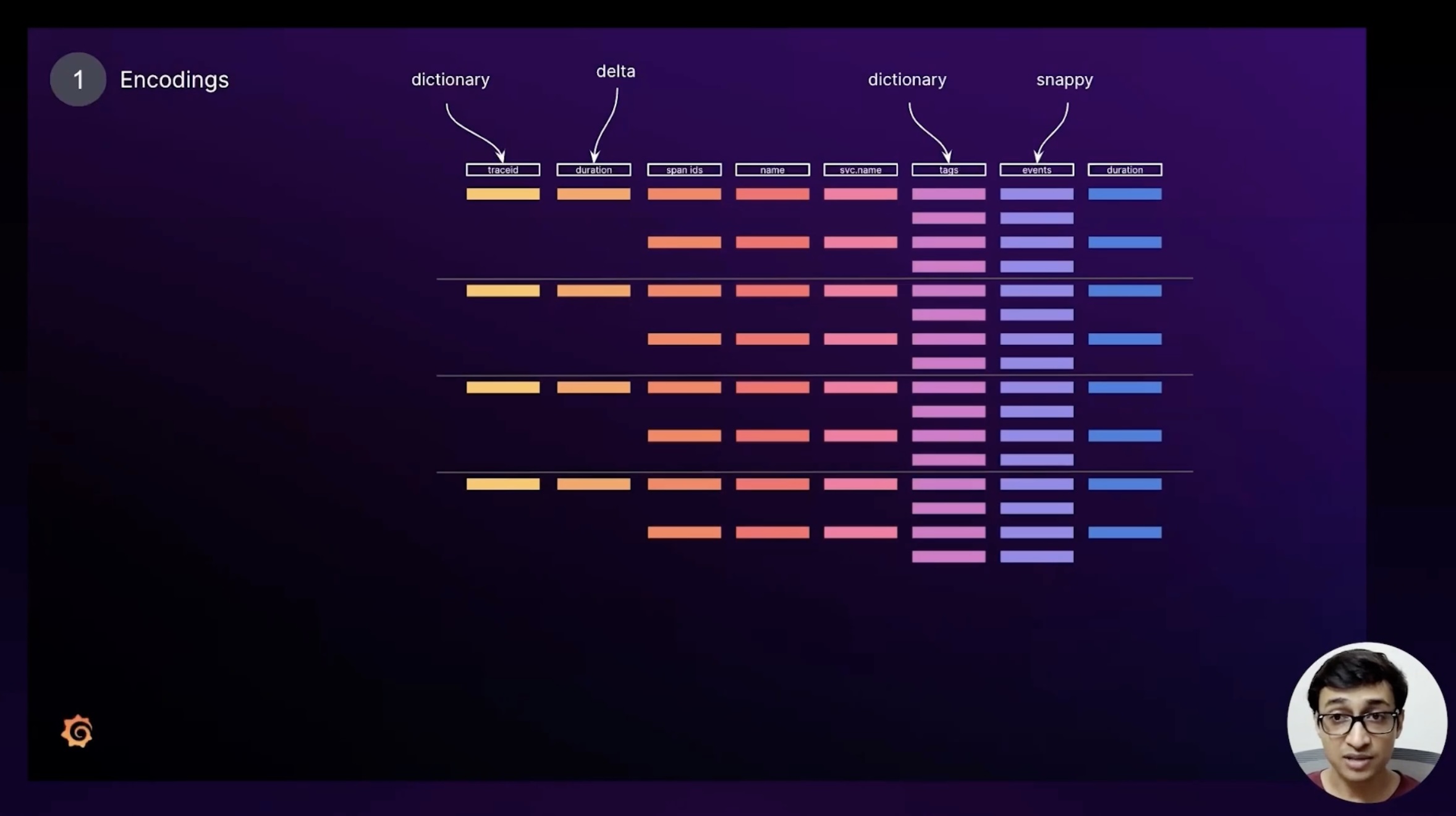
The first one is encoding flexibility: we can pick a compression or encoding strategy per column, tuned to the column’s data type.
For example, a duration column full of integers works great with Delta encoding; a tags column that’s mostly strings benefits from dictionary encoding; and an events column that we don’t need to search can be compacted with Snappy just to save space. Each column can be encoded differently yet still live inside the same Parquet block, which keeps storage tight and search-friendly.
Trace ID Search
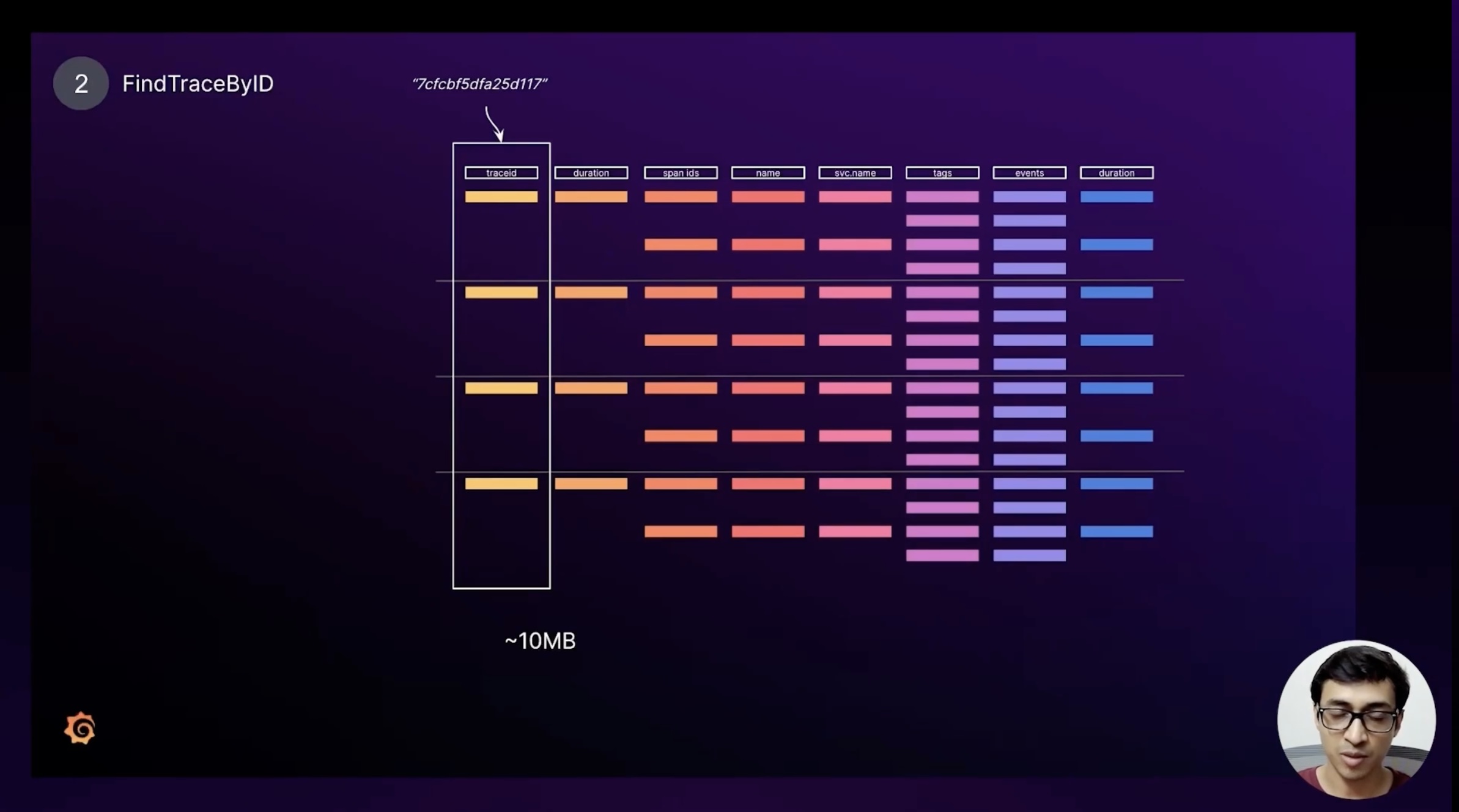
Next we look at how trace-by-ID lookups behave on a Parquet block. When Tempo receives a request for a specific trace ID we only scan the trace ID column—as you probably guessed—but that column is two orders of magnitude smaller than the full dataset. In the example it weighs in at about 10 MB while the entire block was roughly a gigabyte.
That difference makes the scan extremely efficient. Once we find the match we can skip the preceding rows and read only the row we care about, further reducing IO. Finally, when it’s time to render the trace, we convert that row back into protobuf and display it in Grafana. With the basics covered we can now look at richer query shapes.
Attribute search

The next scenario is querying by attributes—think cluster, namespace, or any of the selectors users rely on. These values live in the span or resource tags, so we scan the tags column directly. Just like the trace ID column, the tags column is an order of magnitude smaller than the full block, which keeps the scan cheap.
Because we dictionary-encode tags, Tempo can very quickly check whether the queried term exists. If the dictionary lookup fails we can skip past the column entirely; if it succeeds we only read the rows that reference that dictionary entry. Either way, we avoid touching the rest of the trace payload until we’ve narrowed the candidate set dramatically.
Dynamic schema
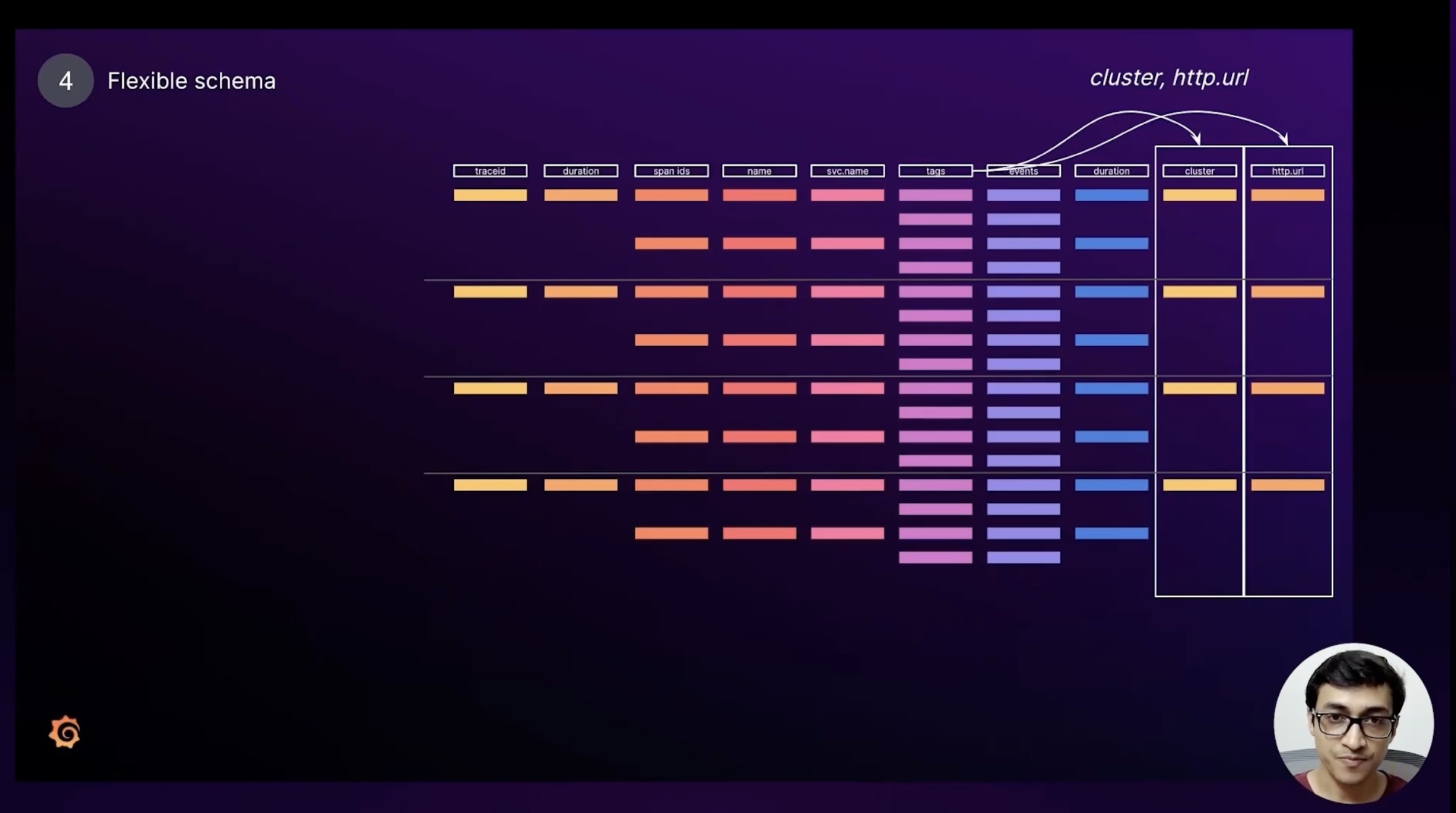
The final feature that excites us is Parquet’s flexible schema. We can add new columns without changing how existing columns are queried. In practice we maintain an opinionated list of high-confidence columns—cluster, namespace, HTTP URL, and a few others—and we materialize them out of the generic tags column into their own dedicated columns.
Once they have first-class columns, queries like “cluster=foo AND http.url=confronto.com” are just another narrow column scan, which is again an order of magnitude smaller than the full file. That lets us keep latency low even as we enrich the schema with more fields over time. Longer term we’re exploring fully dynamic schemas, where every unique tag becomes its own column. We already have a proof of concept running locally, but we want more experimentation before shipping it to production.
On-disk format
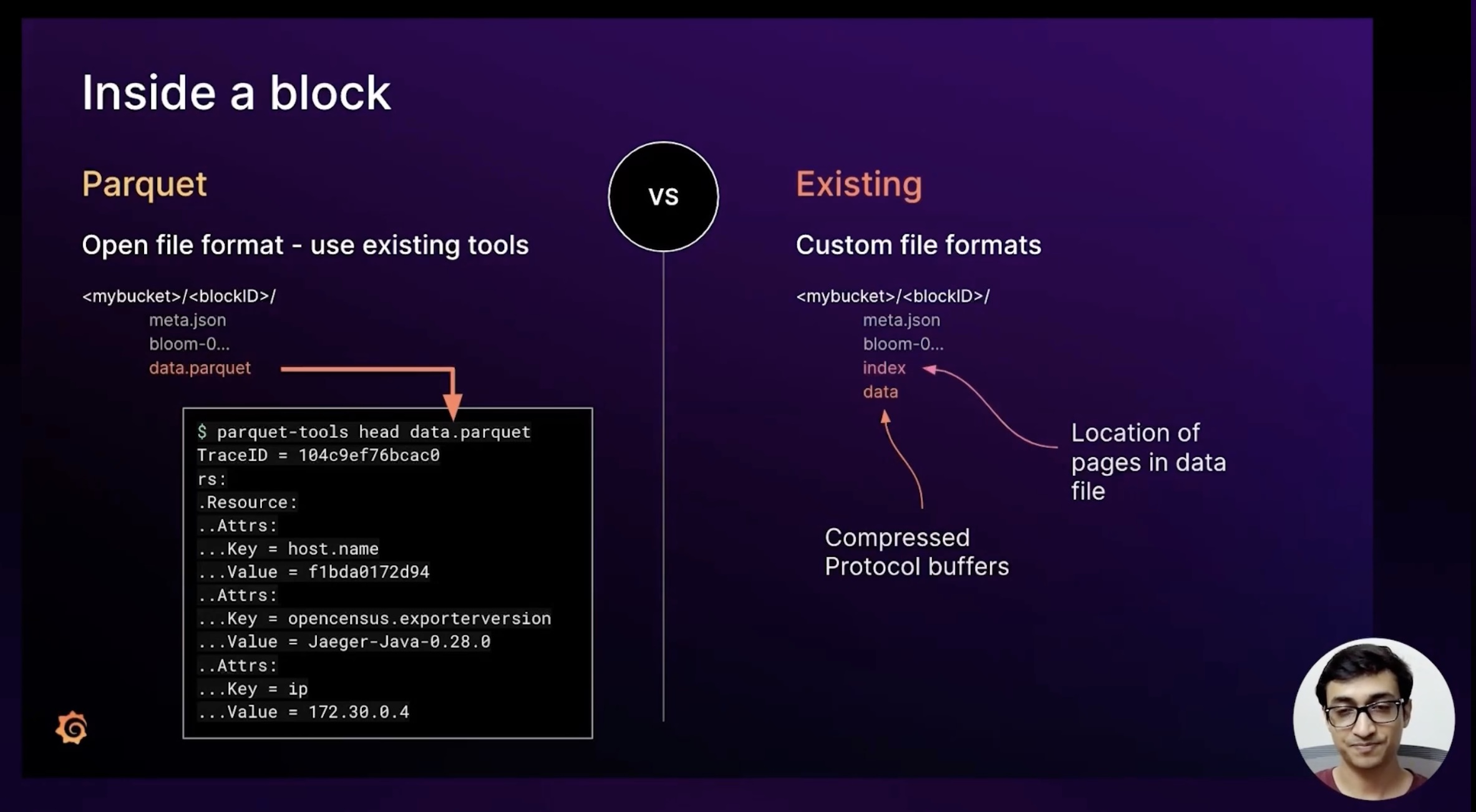
Now let’s zoom out and see how Parquet data sits on disk. Tempo batches traces from the slides above into Parquet blocks and stores them in object storage. The bucket hierarchy is simple: bucket ID at the top, block IDs beneath it, and inside each block we keep metadata files, Bloom filters, and the Parquet payload itself.
Because everything is an open format, we can point off-the-shelf tooling at any block to inspect row counts, column sizes, or even preview the encoded data. That transparency is handy for debugging and gives us confidence that what we store is exactly what we’ll be able to read back when Grafana needs it.
This approach stands in contrast to today’s custom format, where we append compressed protobuf payloads into a bespoke data file plus a sidecar index that lists page locations. We even ship a CLI to trawl those binary files, but they aren’t open or inspectable the way Parquet is.
Closing remarks
And that’s really the heart of this proposal. Everything I covered here lives in an open design doc and PR on the Tempo repo—we’d love feedback on the storage layout, the schema work, and the roadmap toward dynamic columns. Please jump in with suggestions or comments; we’re eager to iterate with the community before we ship this to production.
Link to original proposal from April 2022.